1 简介
之前我们接触的SQL命令的结果,一般都是逐行的。即SQL命令返回的结果,都是来自原表的同一行。Window Function则赋予了我们在SQL 结果中,获得来自一组行的数据的能力。这样的组被称为「Window」。
Window Function最鲜明的特征是OVER关键字。如果 以一个函数有OVER子句,则此函数为Window Function。反之,如果这个函数不带OVER子句,则这个函数是简单的聚合(Aggregate)函数或者标量(Scalar)函数。Window Function在函数和OVER子句之间,还可能带有FILTER子句。
Window Function的语法结构如下:

不同于普通的函数,Window Function不能使用Distinct子句。另外,Window Function只能出现在查询结果中和ORDER BY后面。
Window Function可以划归为的两种不同类型:聚合窗函数(Aggregate Window Function)和内建窗函数(Built-in Window Function)。每个聚合窗函数也可以当做普通的聚合函数使用(只需要舍去OVER和FILTER子句即可)。内建窗函数,也可以通过合适地配置OVER子句从而具备聚合函数的功能。在应用中,我们也可以通过sqlite3_create_window_function()接口(C)来自定义新的聚合窗函数。
下面是使用内建的row_number()窗函数的例子:
1 | CREATE TABLE t0(x INTEGER PRIMARY KEY, y TEXT); |
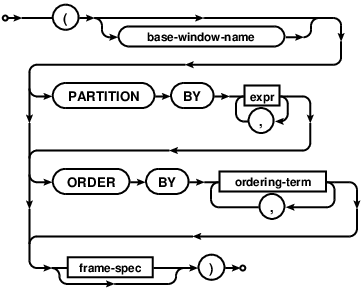
row_number()窗函数函数可以每行添加一个行号。行号的顺序通过OVER后面的ORDER BY y确定。注意,OVER后面的ORDER BY y不会影响SELECT返回的查询结果的顺序。在上面的例子中,SELECT返回的顺序还是根据x来排序的。比对上面的「Window function invocation」图,OVER后的子句体称为window-defn。我们还可以在SELECT语句中通过WINDOW子句来声明named window-defn
1 | SELECT x, y, row_number() OVER win1, rank() OVER win2 |
WINDOW子句,应当位于HAVING之后,ORDER BY之前。
2 聚合窗函数
在这个部分我们假设所有的数据库的结构都是:
1 | CREATE TABLE t1(a INTEGER PRIMARY KEY, b, c); |
聚合窗函数类似于一般的聚合函数,添加聚合窗函数不会改变查询返回的行数。相反,聚合窗函数会将于「Window frame」中运行的得到的聚合结果添加到原本的每一行结果中。例如
1 | -- The following SELECT statement returns: |
在上面的例子中,我们要做的将本行与上下两行的结果拼起来,而上下行关系,是根据OVER子句中的ORDER BY来确定的。
2.1 PARTITION BY 子句
为了计算窗函数,查询的返回结果通过PARTITION BY子句分割成多个「partitions」。PARTITION BY类似于GROUP BY,可以将查询结果中,于PARTITION BY后的window-defn所指定列拥有相通值的行组成组。若没有PARTITION BY子句,则所有的查询结果组成一个单一的组。窗函数在各个「partition」上运行。
例如
1 | -- The following SELECT statement returns: |
在上面的查询例子中,PARTITION BY c将查询结果划分成了三个Partition。第一个Parition的c = one,第二个Partition的c = three,第三个Partition的c = two。注意,Partiion的划分,及其后续的的ORDER BY的排序,和最终查询结果的顺序是没有关系的。上面的查询的例子的输出也可能是:
1 | -- The following SELECT statement returns: |
2.2 Frame Specification
Frame Specification是OVER子句的一个部分,规定了聚合窗函数读取的输出行的范围。frame-spec在window-defn中的位置如下:
frame-spec包含如下四个部分:
- Frame type: either ROWS, RANGE or GROUPS;
- A starting frame boundary;
- An ending frame broundary;
- An EXCLUDE clause;
细节的语法结构如下:
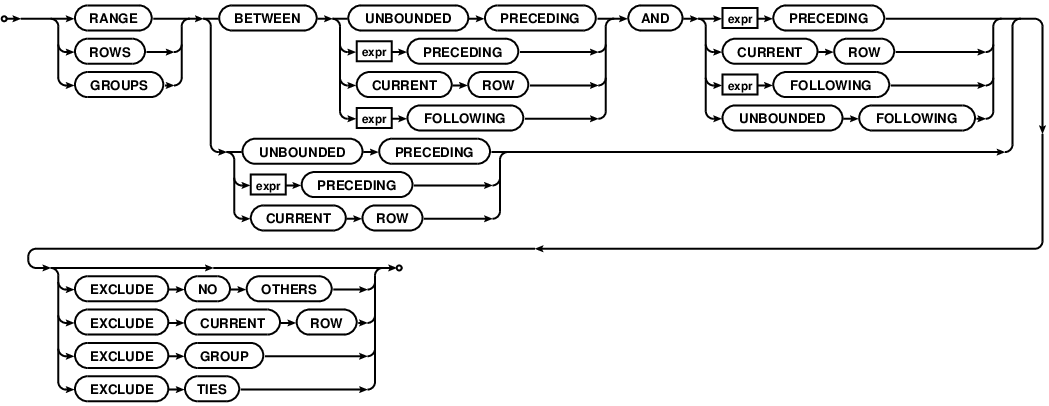
其中ending frame boundary可以被省略,此时默认情况下ending frame boundary默认为 CURRENT ROW。
如果frame type为RANGE或者GROUPS,那么在ORDER BY所指定的列上具有相同值的行被归为一组「peers」。如果没有ORDER BY,那么所有的行归于一组Peer。注意Peers总是属于相同的frame。
默认的frame-spec为
1 | RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW EXCLUDE NO OTHERS |
默认的配置的意思是,聚合窗函数从Partition的开头开始读取直到当前的行的所有Peers。同Peer组的行对从窗函数获取的返回值是相通的(其Window frame是相同的)。例如
1 | -- The following SELECT statement returns: |
关于Frame的更多细节,参考出处原文(页面顶部)
2.3 FILTER 子句

如果出现了FILTER子句,那么只有expr指定的行才会被包含到window frame中。这里的FILTER不会过滤查询结果,只是决定了窗函数作用的范围。
3 内建窗函数
内建窗函数也具备和聚合窗函数同样的PARTITION BY子句功能:每个行都从属于一个Partition,而每个Partition被单独地进行处理。ORDER BY的作用,我们在下面进行阐述。有一些特定的窗函数(rank(), dense_rank, percent_rank and ntile())采用了peer group的概念(rows within the same partition that have the same values for all ORDER BY expressions)。此时frame-spec中frame type(ROWS, GROUPS, RANGE) 就不起作用了。
SQLite支持如下11个内建的窗函数
row_number(): 当前行位于Partition中的位置(行号),从1开始排列,顺序由窗函数的ORDER BY决定。rank(): 每一个Group(同一个Partition内在ORDER BY指定的列上具有相同值的行归于一个Group)中的第一个peer(行)的row_number值。rank获取的序号可能是不连续的。dense_rank(): 相比于rank(), 压缩了序号的间隙,得到的序号总是连续的。从1开始排。percent_rank(): 将rank转化成百分比,等于(rank - 1)/(partition-rows - 1)。如果只有一个组,返回0.cume_dist(): 累积分布,等于row-number/partition-rows。ntile(N): 参数N为整数,这个函数将partition划分为尽可能均匀的N份,并为每份分配一个1到N的整数,顺序由ORDER BY决定(若无ORDER BY,则为乱序)。如果需要的话,较大的组会先出现。lag(expr)lag(expr, offset)lag(expr, offset, default): 返回对上一行执行expr得到的结果。如果没有上一行,返回空。可以通过offset修改偏移量(如设为2,返回往上数第二行执行结果,必须为费复制)。offset为0表示对当前行执行。default表示目标行不存在时需要返回的默认值。lead(expr)lead(expr, offset)lead(expr, offset, default): 和lag函数类似,不过是向下获取。first_value(expr): 返回第一个行的数据last_value(expr): 返回最后一行的数据nth_value(expr, N): 返回第N行的数据。